
Thinking linking – Sembl data
Because Sembl will be a system for generating data, I’ve been worrying about how we can ensure that the data it generates is well-structured so that it is machine-readable and thereby linked to other data and reusable in aggregation. But because both linked open data (LOD) and Sembl itself are all about relationships, whenever I try to think it through my thoughts become tangled.
In this post I attempt to order my thoughts around linked data as it pertains to Sembl – specifically, I seek a better understanding of entities, identities and similitude. Whoa. We had better start with a picture.
This is a cannon in the collection of the National Museum of Australia. If you look at our information about the cannon, you can see that it was:
- on board HMB Endeavour
- used by Captain James Cook
- jettisoned on the Great Barrier Reef after the ship ran aground
- made circa 1725–50
- used 1768–70
- jettisoned 11 June 1770
- salvaged 1969
It would be great if all those references – to the Endeavour, Cook, the Great Barrier Reef and all those dates – were linked to all the other references to those things on the web. Then, you could find out much more about the boat, the person, the place and the time.
That is the dream of linked data – to enable machines to recognise an entity wherever it is mentioned on the world wide web.
So what does it require of us as a web publisher or as a designer of a system for generating online data? Any time we publish a chunk of web content, we should bundle in with the publication a set of pointers to relevant places, times, people and organisations associated with the entities mentioned in that content. In this way, we forge a link between our mention of Captain James Cook and all his other mentions elsewhere on the web. Tools for doing this do exist, but they remain curiously rare. (Try searching for a WordPress plugin that adds linked data to your blog content.)
But actually, identity-tracking is only one part of the LOD dream; there are many kinds of relationships other than ‘is the same as’. Imagine if there was a universally comprehensible language for describing the various relationships one entity has with other entities.
In my description, the cannon was
- ‘on board’ the Endeavour
- ‘used by’ Cook
- ‘jettisoned’ on the reef
But it could just as easily have been
- ‘part of’ the Endeavour
- ‘owned by’ Cook
- ‘thrown onto’ the reef
How do we know how to cite the relationship so that the machines can parse it as we would want? That’s where ontologies and RDF triples (or quads!) come into the picture – whenever the relationship between two entities is more complex than ‘[x] [is the same as] [y] (according to [z])’. But that’s also where it becomes tricky to link data. We need a common vocabulary to describe and to arrange relationships that are not necessarily common or even clear to one person – let alone a global population!
There are many different ontologies out there and emerging; but so far none works especially well for museum objects. In fact, as I write this, there are discussions going on about sharing vocabularies for LODLAM (aka linked open data in libraries, archives and museums) as a step toward a shared understanding.
It’s difficult to imagine a single system for describing objects that would be universally agreeable. And as Tim informs me, the point is rather to connect the vocabularies rather than settle on one. But here’s a thought-stream about primary elements of museum object relationships: we would probably want to identify the object’s relationships to
- people: ‘created by’, ‘used by’, ‘owned by’
- places: ‘created at’, ‘used at’, ‘stored at’, and
- events: ‘associated with’ – although vague, that concept seems important for museum objects whose potency is often by association with significant people or events
- activities: ‘used during’ or ‘used for’
- other objects: ‘made of’, ‘type of’, ‘part of’, ‘contains’, ‘used with’, ‘replaced’, ‘prototype of’
And so on. Although perhaps anything much more than that is more trouble than it’s worth? (I don’t know!)
And… Sembl data?
In the case of Sembl, data that players generate is intrinsically linked: the challenge of the game is to find a way in which one object relates to another. As a player you might draw on the machine-readable ‘other objects’ links; but if you relied solely on them, you might not fare very well in the game because to win points the relationship has to be ‘interesting’ – as defined by the other humans playing the game.
You might improve your chances if you identified a less direct relationship through a series of steps through the linked data. For example, you might find out that the seed object was used by someone who was the daughter of someone who was integral to an event that is represented by an object that you then select to play in the game. But that’s still a machine-like relationship and therefore a bit… uninteresting.
Part of the game’s awesomeness is that players generate new kinds of relationships – relationships that fit no predetermined ontological structure and which, sometimes, make you think differently. One key to this novelty is that players forge connections not from one thing to another but from one facet of a thing to another facet of another thing.
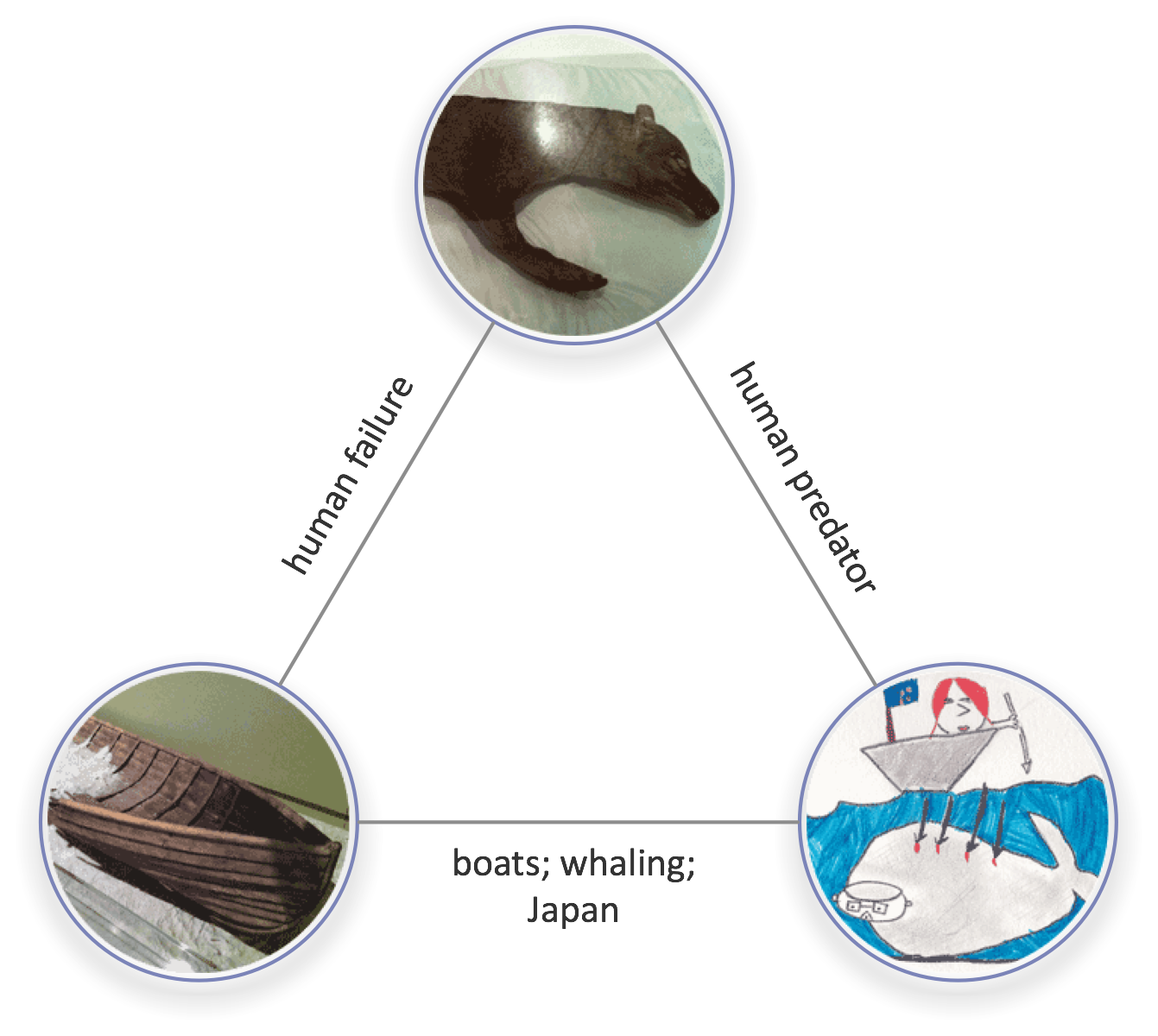
Whaleboats and thylacine are not intrinsically linked; the link coalesces between a particular facet of each thing. Players identify (describe) those facets as part of the game, as illustrated above.
As well as faceted, connections can be figurative or playful. In one game the above Thylacine ‘puppet’ was linked to a Welsh organ because the former is organ-less. In another game, 10-year-old children linked the Welsh organ to a set of convict leg irons because both work with keys.
Imagine trying to develop an ontology that worked for all those different linguistic twists. It would be as mind-melting as that Chinese animal taxonomy that Borges described; and it would be ever inadequate. Similitude resists containment.
So… Sembl and linked data?
After all this thinking – and the above is a lot clearer, I believe, than the crazy diagram I made when I started thinking this through – I reckon: we should not worry about creating linked data within the Sembl app. We should, however, endeavour to do the following:
- Make the Museum’s collection database do the work of adding linked data about entities mentioned in the description of collection objects. (That’s big, and well beyond me and my Sembl project; but the wheels are in motion.)
- Find a way to link representations of collection items created during gameplay to their entry in the collection database. (Again, this will not be easy although Tim’s object type browser might be a valuable first step.) Maybe the game app can award extra points to teams that link their proposed object to its authoritative Museum representation.
- Capture the descriptive and relational information that players generate and connect it to the relevant fields in the collection database. So in the collection database, each object that has been used in Sembl will have player-generated descriptive and relational augmentation.
Those, then, are my thoughts – de-fuzzed to a degree by what felt like some strenuous mental exertion! What do you reckon? Can you spot any flaws in my thinking? (If so, please share!) Is this post useful for others thinking through linked data in relation to their own collections and applications?




{kind=link}
Sembl is sounding cooler and cooler.
But… why not make linked data within the app? Couldn’t user-generated ontologies be just another form of user-generated content (like tags and comments)? I think the thing with linked data is it is good to re-use whereever possible but, if there is no ontology to map the entity or relationship (“human failure”) you want to describe, then it is trivial to just create that new term.
Couldn’t sembl just: 1) check if the new relationship already exists (& if so use that, because you could then connect to every other entity mapped to, for example, “human failure”) and 2) if it is new, just coin a new relationship within the sembl namespace. e.g.”www.nma.gov.au/sembl/human+failure”?
Hi Richard – and thanks! A user-generated ontology that grows through gameplay – that does sound cool.
My thinking was that because Sembl relationships tend to be novel, the pre-existence would be very rare, so the ontology would grow and grow and each term may never be reused. And even if the concept had been used before, the terminology would most likely differ on the second use (and we would probably not want to require players to check the ontolology during gameplay – especially given that it would be a large and ever-growing set of terms).
But maybe the ontology could be used to interesting effect even if its terms are not applied to multiple chunks of content, by meshing terms within the ontology, for example. So even if there was only one link to ‘human failure’, there might be links to other terms involving ‘human’ and ‘failure’.
Wrestling with issues of ontologies and mechanisms for publishing LOD now that I have started to implement Semantic MediaWiki functionality into the PROV wiki. It’s very early days, however, the opportunity for drawing explicit and interesting relationships between the wiki content is definitely there. Especially looking forward to being able to export the automatically generated RDF to triple stores that SMW produces. I love the idea of game play for mapping these relationships!
Hi Asa,
That sounds exciting. Will you also use the SMW connections within your collection database?
Cath
We are now uploading a lot of content from past online exhibitions onto the wiki. The long term vision is that the pPROV wiki will become a place to Transcribe, Geo-Refrence, Publish, Tag, and Share. All the content will be exportable as RDF (as it is now) and will then be able to be placed in a RDF store where it can be consumed by semantic browsers/services using various protocols e.g. SPARQL. Of course the PROV wiki will also be able to query its own content (it can already do this to an extent) and draw in relevant information from the Linked Data Cloud using SPARQL. It’s such an exciting time to be alive! I have already been navigating the PROV wiki rdf with semantic browsers and also performing some rudimentary SPARQL queries using some generic endpoints (just check my recents tweets!)
Cath,
Other folks in the museum world are grappling with the same issues, so don’t think you’re alone! For example, the CIDOC Documentation Standards Working Group is starting a conversation about Linked Data “design patterns” for cultural history:
http://network.icom.museum/cidoc/working-groups/documentation-standards/docstandards-lddp.html
We’d love you to be part of that conversation.
Richard
Hey, Richard, thanks for your encouragement :) and that pointer. It is not so easy to grok technical documentation; eyes glaze over fairly quickly. I suppose that is part of the problem that Mike Ellis identifies.
It’s great to see the questions on that page composed in plain English – although I’m not sure I interpret the questions correctly (if there is a correct way to interpret them). Eg my response to the question: “To what degree should museum object Linked Data identifiers contain “meaning”?” is: Is not meaning the whole point???
Also, much as I like the idea of using design patterns to start to generate the lexicon, I can’t mentally match that generic concept with what you’re doing on that page.
In short, I’m very interested in linked data because I understand the potency of its potential (ack, tautological thinking alert!); and I’m keen to engage at the point of applying and testing the technology, but I’m not sure how useful I can be in the process of developing the functionality.
Great post, Cath – one of the clearest explainers of “Why Linked Data?” that I’ve read, and I’ll be fascinated to see where your project goes, and why!
My general position on Linked Data hasn’t changed since I wrote my post, and my reasons for remaining sceptical haven’t either.
I spend maybe half my time working with education and cultural technical web developers and half my time with web developers from outside these spheres. Although there is a hardcore enthusiasm for linked approaches *inside* our sectors (and – don’t get me wrong – this may be enough for it to be worth doing!) – the penetration of LD into the mainstream of web development is absolutely minimal. This is despite some years (maybe a decade, I don’t know?) of evangelism about the [fairly obvious] benefits of a linked world view.
I quite often carry out a straw poll of the non-CH/non-education web devs I know, asking them what they know or use when transporting data around, and without exception the answer is API-based approaches. These guys know little and care little about the potential “perfect data” scenario offered by semantic approaches. They just want to build stuff…
I’m not quite sure what this means, but it troubles me on lots of levels. For starters, there just aren’t any demonstrators that are any good – and by “good” I mean impressive enough that they make you sit up and say – “damn, I couldn’t have done that with an API – what the hell IS this new thing, I’ve gotta get me some of that!”. Secondly, some of the things which underpin LD – solid, stable, enduring URI’s or – as you say – reaching an agreement on what concept X is or means – for example, are actually pretty shaky. Finally, and I maintain this as a total advocate of open data (and someone who is vaguely but not totally technical) – it is just too damn hard to get started! Ontologies make normal developers glaze over and normal humans die of fear :-)
I believe quite strongly that these kinds of approaches need a groundswell of activity to really make them happen – and I just don’t see that in the mainstream. Maybe there’s a “…yet” there somewhere, but we seem to have been saying “…yet” for a very very long time…
Thanks much for sharing those thoughts, Mike. Perhaps we need the tech-dev LD-enthusiasts to persuade the tech-dev API-enthusiasts to get on board the LD train. I can evangelise on linked data in principle, but I agree with you, the proof is in the in-practice pudding.
From a technical perspective, it’s also interesting to think about the various ways that a device that represents relationships between objects in the context of a game that focuses entirely on the relationships.
A lot of the above discussion has made reference to the problem of redundant or unused formal relationships, but we can turn this around – at the end of a game, we want to extract useful data about the kinds of relationships identified, clean it up, and add it to an accumulating store of info about common relationships between objects.
I’m curious: anyone know of any good tools for detecting semantic similarity, given short sentences?
Hey Jon, welcome to the Labs blog. There’s a word missing from your first sentence, perhaps: “From a technical perspective, it’s also interesting to think about the various ways that a device that represents relationships between objects [works] in the context of a game that focuses entirely on the relationships.” (Though I’d still like some elaboration on your point there! By ‘device’ do you mean iPad? Or linked data? Or..?)
And does the iOS NSLinguisticTagger Class Reference you mentioned the other day answer your own question about merging similar but differently-described relationships like ‘looks like metal’ and ‘metallic’, in that it can identify the stem of the word?
Skimming the Wikipedia page on part-of-speech tagging, I’m wondering also whether we’re getting into territory where – to date – humans are simply better than machines. Maybe parts of the linked data and semantic disambiguation solution should be crowdsourced.
Hi Cath, all:
I’m just catching up here, and while i don’t think it relates to any of the technical issues involved, I think Derek Robinson’s piece The HipBone Games, AI and the rest may give you some hints of the possibilities I’ve seen:
http://www.scribd.com/doc/47035699/Hipbone-Games-AI-and-the-rest-Derek-Robinson
Mark you, this was written a little over ten years ago, so it’s more “vision” than “realization”.
Hello – really good to see this kind of work. I completely agree that linked data should be more *fun* to create and work with. I’ve been thinking along similar lines in terms of narrative information for TV/radio programmes – it’d be great if script-writers could produce linked data about plot/action as they wrote.
Anyway, I was thinking around the same thing of users generating new properties/relationships, rather than having to define every possible relationship up front. I see what you mean about the possible danger of redundant/single-use relationships. Partly I’d see that as less of a problem than actually generating the data (in line with TimBL, I’d encourage people to create data, then we can work out how to improve the messiness later).
BUT – seeing as what you’re building is a game, why not have an extra part of the game, in a Luis Von Ahn style, where the game is to match similar relationships together? (I guess this is what you mean by the crowdsourcing reference above, but that could be part of the game, too…)
Hi Paul!
Belatedly responding to your comment. Your vision of scriptwriters adding linked data as they write is interesting. Reminds me of my time working at the National Archives, where because it’s the agency responsible for records management across the Commonwealth government, staff were well versed in creating useful email subject lines, naming files by high-level function and activity, etc etc. It’s quite an effort to shift your work processes to do that as you go, but I wholeheartedly agree that the further upstream that meta-thinking is done, the better. And I’m convinced that games like Sembl (and other metadata games, and perhaps also Luis’ games), enable people to practise meta-cognition, and that that’s a really important skill in the 21st century.
I have indeed started to imagine that within the game you could gain points for making a nice edit that clarifies or makes succinct an existing relationship. And yes, in browsing the (aggregated game data) web of resemblance that Sembl will populate, it’d be very cool if you could also edit relationships for brevity/clarity, and yeah, suggest mergers. Or maybe just link them. I guess this could be called a related relationship?! Would you have to then define the relationship between the relationships? Now that would be good meta-cognition practice :)
Cath