
Thinking linking – Sembl data
Because Sembl will be a system for generating data, I’ve been worrying about how we can ensure that the data it generates is well-structured so that it is machine-readable and thereby linked to other data and reusable in aggregation. But because both linked open data (LOD) and Sembl itself are all about relationships, whenever I try to think it through my thoughts become tangled.
In this post I attempt to order my thoughts around linked data as it pertains to Sembl – specifically, I seek a better understanding of entities, identities and similitude. Whoa. We had better start with a picture.
This is a cannon in the collection of the National Museum of Australia. If you look at our information about the cannon, you can see that it was:
- on board HMB Endeavour
- used by Captain James Cook
- jettisoned on the Great Barrier Reef after the ship ran aground
- made circa 1725–50
- used 1768–70
- jettisoned 11 June 1770
- salvaged 1969
It would be great if all those references – to the Endeavour, Cook, the Great Barrier Reef and all those dates – were linked to all the other references to those things on the web. Then, you could find out much more about the boat, the person, the place and the time.
That is the dream of linked data – to enable machines to recognise an entity wherever it is mentioned on the world wide web.
So what does it require of us as a web publisher or as a designer of a system for generating online data? Any time we publish a chunk of web content, we should bundle in with the publication a set of pointers to relevant places, times, people and organisations associated with the entities mentioned in that content. In this way, we forge a link between our mention of Captain James Cook and all his other mentions elsewhere on the web. Tools for doing this do exist, but they remain curiously rare. (Try searching for a WordPress plugin that adds linked data to your blog content.)
But actually, identity-tracking is only one part of the LOD dream; there are many kinds of relationships other than ‘is the same as’. Imagine if there was a universally comprehensible language for describing the various relationships one entity has with other entities.
In my description, the cannon was
- ‘on board’ the Endeavour
- ‘used by’ Cook
- ‘jettisoned’ on the reef
But it could just as easily have been
- ‘part of’ the Endeavour
- ‘owned by’ Cook
- ‘thrown onto’ the reef
How do we know how to cite the relationship so that the machines can parse it as we would want? That’s where ontologies and RDF triples (or quads!) come into the picture – whenever the relationship between two entities is more complex than ‘[x] [is the same as] [y] (according to [z])’. But that’s also where it becomes tricky to link data. We need a common vocabulary to describe and to arrange relationships that are not necessarily common or even clear to one person – let alone a global population!
There are many different ontologies out there and emerging; but so far none works especially well for museum objects. In fact, as I write this, there are discussions going on about sharing vocabularies for LODLAM (aka linked open data in libraries, archives and museums) as a step toward a shared understanding.
It’s difficult to imagine a single system for describing objects that would be universally agreeable. And as Tim informs me, the point is rather to connect the vocabularies rather than settle on one. But here’s a thought-stream about primary elements of museum object relationships: we would probably want to identify the object’s relationships to
- people: ‘created by’, ‘used by’, ‘owned by’
- places: ‘created at’, ‘used at’, ‘stored at’, and
- events: ‘associated with’ – although vague, that concept seems important for museum objects whose potency is often by association with significant people or events
- activities: ‘used during’ or ‘used for’
- other objects: ‘made of’, ‘type of’, ‘part of’, ‘contains’, ‘used with’, ‘replaced’, ‘prototype of’
And so on. Although perhaps anything much more than that is more trouble than it’s worth? (I don’t know!)
And… Sembl data?
In the case of Sembl, data that players generate is intrinsically linked: the challenge of the game is to find a way in which one object relates to another. As a player you might draw on the machine-readable ‘other objects’ links; but if you relied solely on them, you might not fare very well in the game because to win points the relationship has to be ‘interesting’ – as defined by the other humans playing the game.
You might improve your chances if you identified a less direct relationship through a series of steps through the linked data. For example, you might find out that the seed object was used by someone who was the daughter of someone who was integral to an event that is represented by an object that you then select to play in the game. But that’s still a machine-like relationship and therefore a bit… uninteresting.
Part of the game’s awesomeness is that players generate new kinds of relationships – relationships that fit no predetermined ontological structure and which, sometimes, make you think differently. One key to this novelty is that players forge connections not from one thing to another but from one facet of a thing to another facet of another thing.
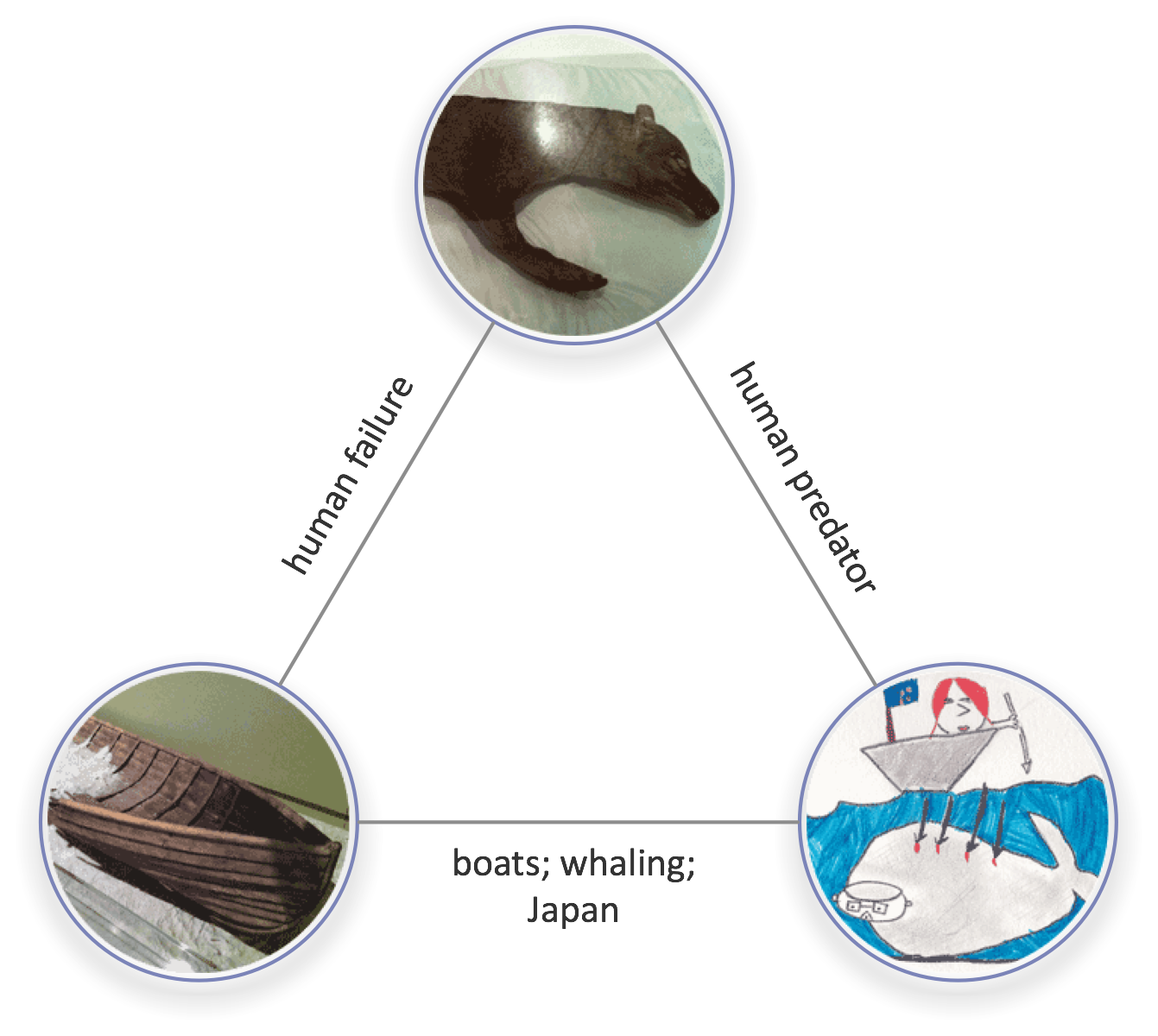
Whaleboats and thylacine are not intrinsically linked; the link coalesces between a particular facet of each thing. Players identify (describe) those facets as part of the game, as illustrated above.
As well as faceted, connections can be figurative or playful. In one game the above Thylacine ‘puppet’ was linked to a Welsh organ because the former is organ-less. In another game, 10-year-old children linked the Welsh organ to a set of convict leg irons because both work with keys.
Imagine trying to develop an ontology that worked for all those different linguistic twists. It would be as mind-melting as that Chinese animal taxonomy that Borges described; and it would be ever inadequate. Similitude resists containment.
So… Sembl and linked data?
After all this thinking – and the above is a lot clearer, I believe, than the crazy diagram I made when I started thinking this through – I reckon: we should not worry about creating linked data within the Sembl app. We should, however, endeavour to do the following:
- Make the Museum’s collection database do the work of adding linked data about entities mentioned in the description of collection objects. (That’s big, and well beyond me and my Sembl project; but the wheels are in motion.)
- Find a way to link representations of collection items created during gameplay to their entry in the collection database. (Again, this will not be easy although Tim’s object type browser might be a valuable first step.) Maybe the game app can award extra points to teams that link their proposed object to its authoritative Museum representation.
- Capture the descriptive and relational information that players generate and connect it to the relevant fields in the collection database. So in the collection database, each object that has been used in Sembl will have player-generated descriptive and relational augmentation.
Those, then, are my thoughts – de-fuzzed to a degree by what felt like some strenuous mental exertion! What do you reckon? Can you spot any flaws in my thinking? (If so, please share!) Is this post useful for others thinking through linked data in relation to their own collections and applications?



{kind=link}